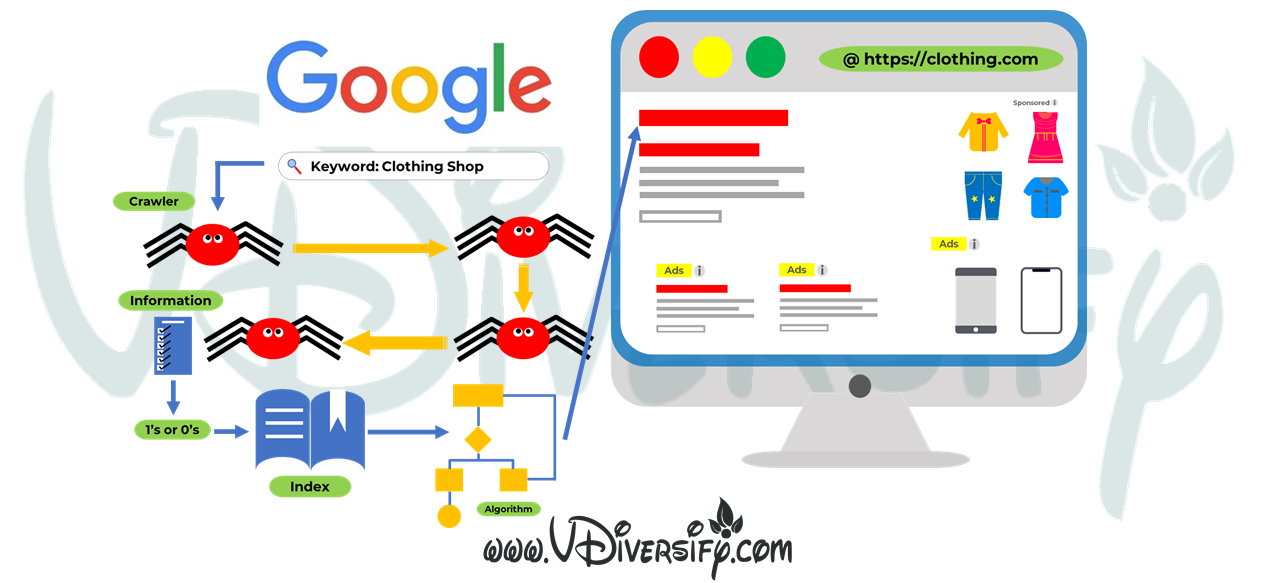
How Search Engines Works? The Basics of Crawling, Indexing & Ranking:
In the last Post of SEO Guide, we have learnt about Why you need SEO? And its importance? Also, we have gone through the Topics of Webmaster Guidelines, especially Google Webmaster Guidelines.
The previous Post thought us about the Search Engines and how they work in order to find the right content over the Internet and submit to the Person who is searching for that content over search engine.
The hardest part of SEO is to make your Website, Pages and Posts to make visible on Search Engines. To make this possible there are things on which we need to work on which is called as How to make your Website rank among the Search Engine Results Pages (SERP’s).
To put in simple terms the Search Engine majorly stands on 3 Key Technical Words.

1. Crawl: Do an audit over the Web against the Search Keyword that the User has typed-in over search engine. Find the most suitable Content, Pages, Posts and Websites and show on SERP’s.
2. Index: A Library of Storage of Search Content over the Web during the process of Crawling. Gather all the content and data ans store securely and make it visible on SERP’s.
3. Rank: Show the search results of the Content that exactly or nearly matches and answers the search query of the User. In simple words order by most relevant to least relevant.
As we have already gone through Search Engine Crawling and Search
Engine Indexing in our previous Post we will not be going in detail as of now.
We have also covered the Topic of Basics on how the Search Engine Works?, Search Engine Crawling & Indexing. If you want check out, Please Visit here. What Is SEO? Types of SEO | SEO Learning Guide

“Hey, I am Sachin Ramdurg, the founder of VDiversify.com.
I am QA/QC Manager, Certified Lead Auditor and Quality Champion. I am an Engineer and Passionate Blogger with a mindset of Entrepreneurship. I have been experienced in Blogging for more than 15+ years and following as a youtuber along with blogging, online business ideas, affiliate marketing, and make money online ideas since 2012.
1 thought on “SEO | How Search Engines Works? The Basics of Crawling, Indexing & Ranking_Part_1:”